Apriori Algorithm - 先验算法,基于数据挖掘和关联规则的推荐算法(三)
前言:上一章我们手动演算了一遍Apriori,在理解了算法的数学逻辑后,我们将在这一章,把数学逻辑转换为代码逻辑。并尝试在代码层面(Java)实现它
上一章传送门:Apriori Algorithm - 先验算法,基于数据挖掘和关联规则的推荐算法(二)
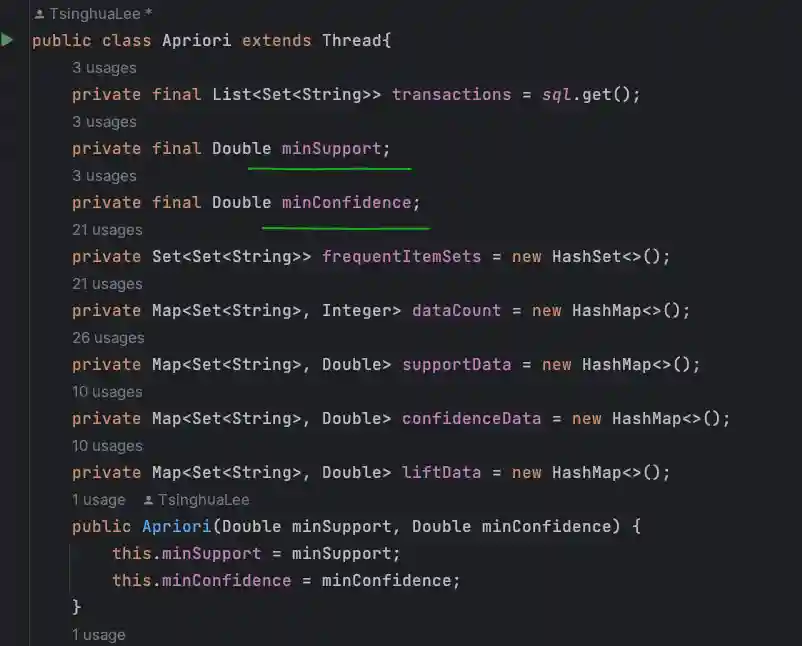
核心参数
首先是2个最关键的参数:
minSupport、minConfidence
以及在运算中使用到的数据项集容器:
transactions(数据源)、frequentItemSets(数据项集)、dataCount(数据出现次数)、
supportData(sup数据)、confidenceData(conf数据)、liftData(lift数据)
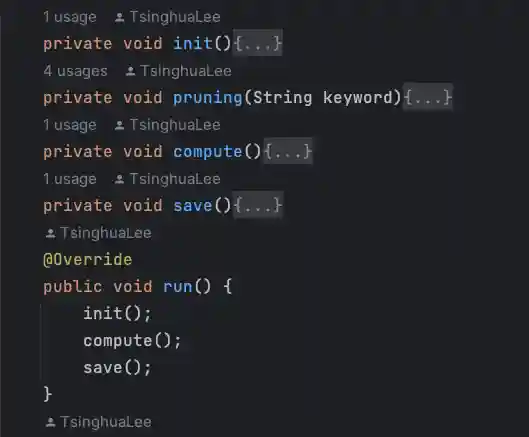
代码流程
这里把流程分为了3步:init() - 构建、compute - 计算、save() - 保存
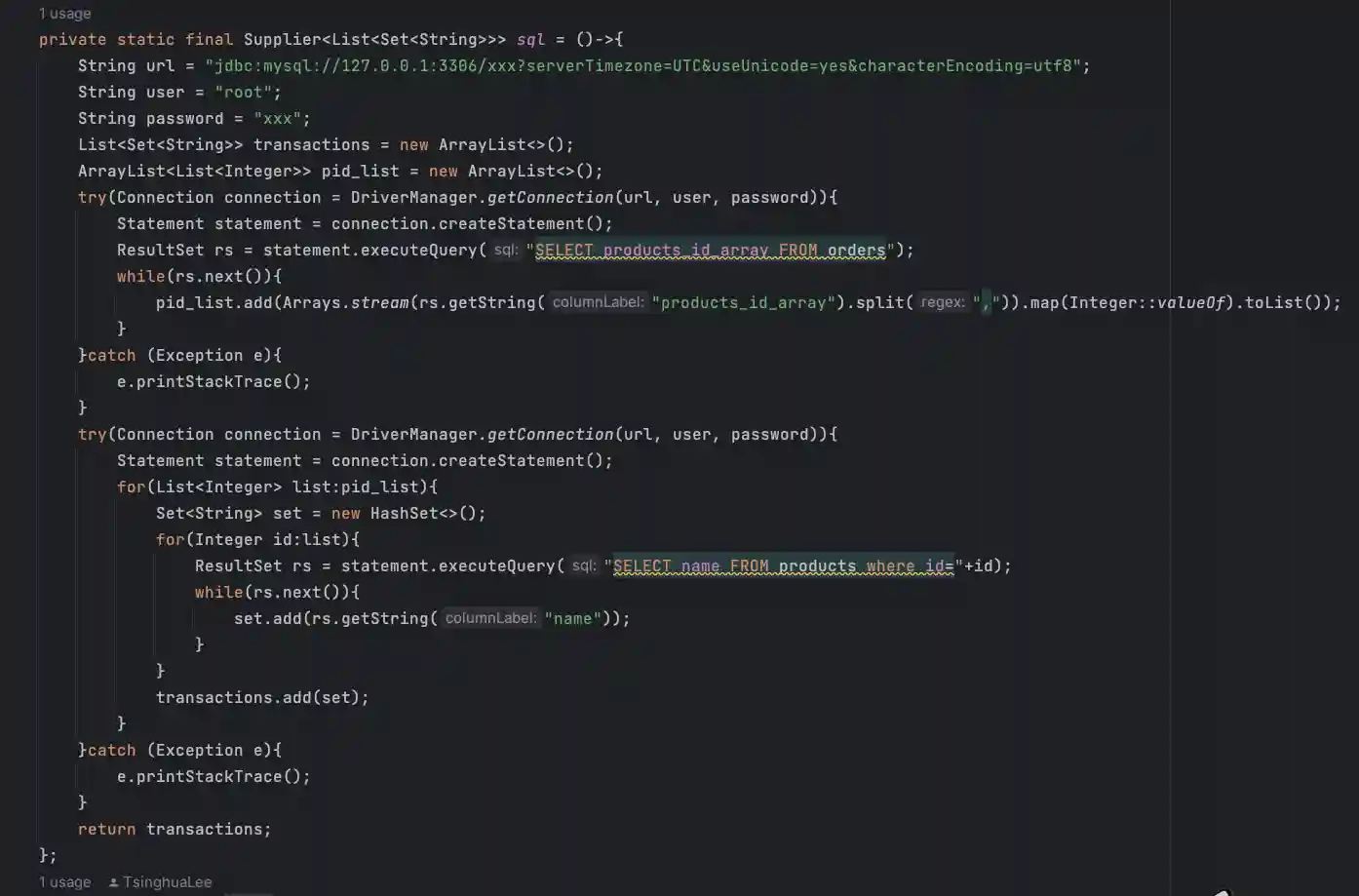
数据获取
数据的获取,我这里使用的SQL数据,10条订单数据。当然,只获取了订单中的商品名字段,读者可以根据自己的喜好去模拟生成自己的数据进行操作。
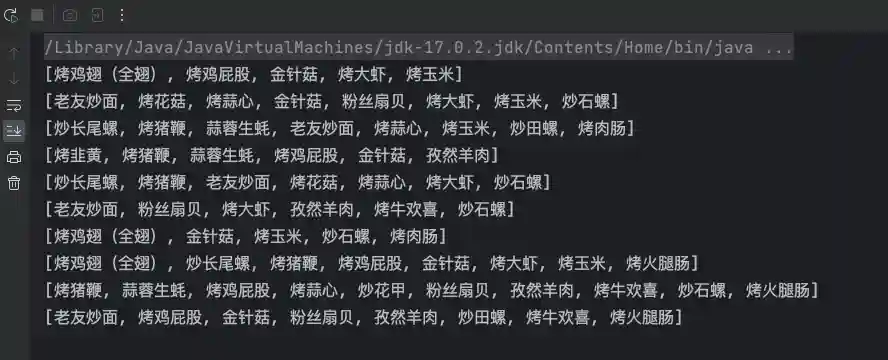
这是源数据的格式:
tips:由于我使用lambda表达式直接获取SQL数据,所以线程的run()方法并没有获取数据这一步操作
构建 - init()
这里我们开始构建数据项集,transactions保存着SQL数据,一切将从transactions开始。分别构建K=1、K=2、K=3项集
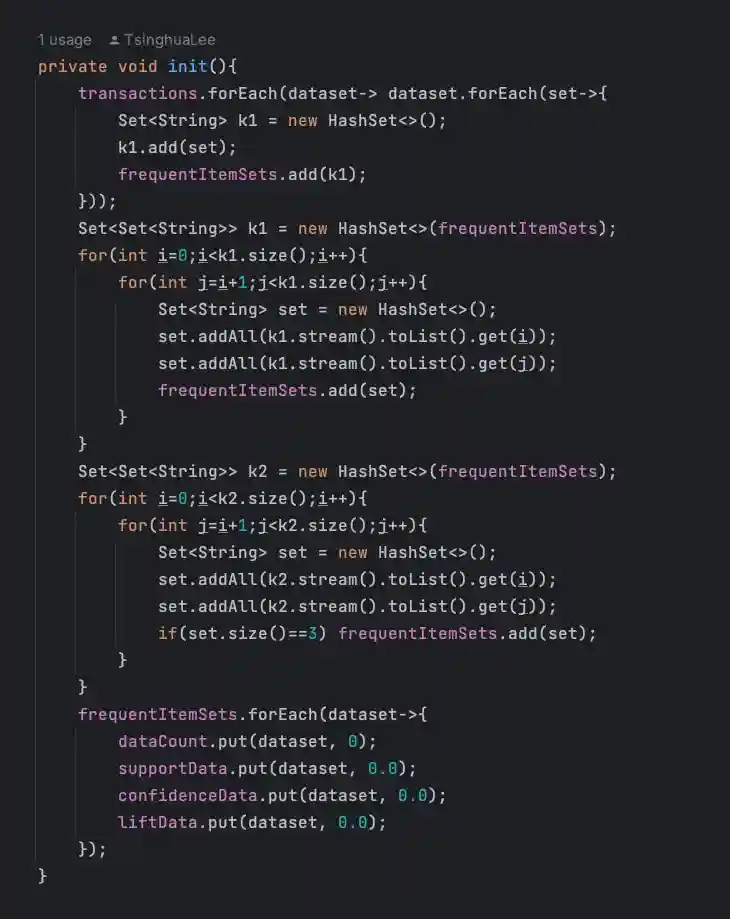
通过以上代码,frequentItemSets、dataCount、supportData、confidenceData、liftData的key将完全同步,并且由key存储所有的数据项集,value则全部赋予初始值:0,未来value将负责保存对应的计算结果。以下为部分数据截图:

计算 - compute()
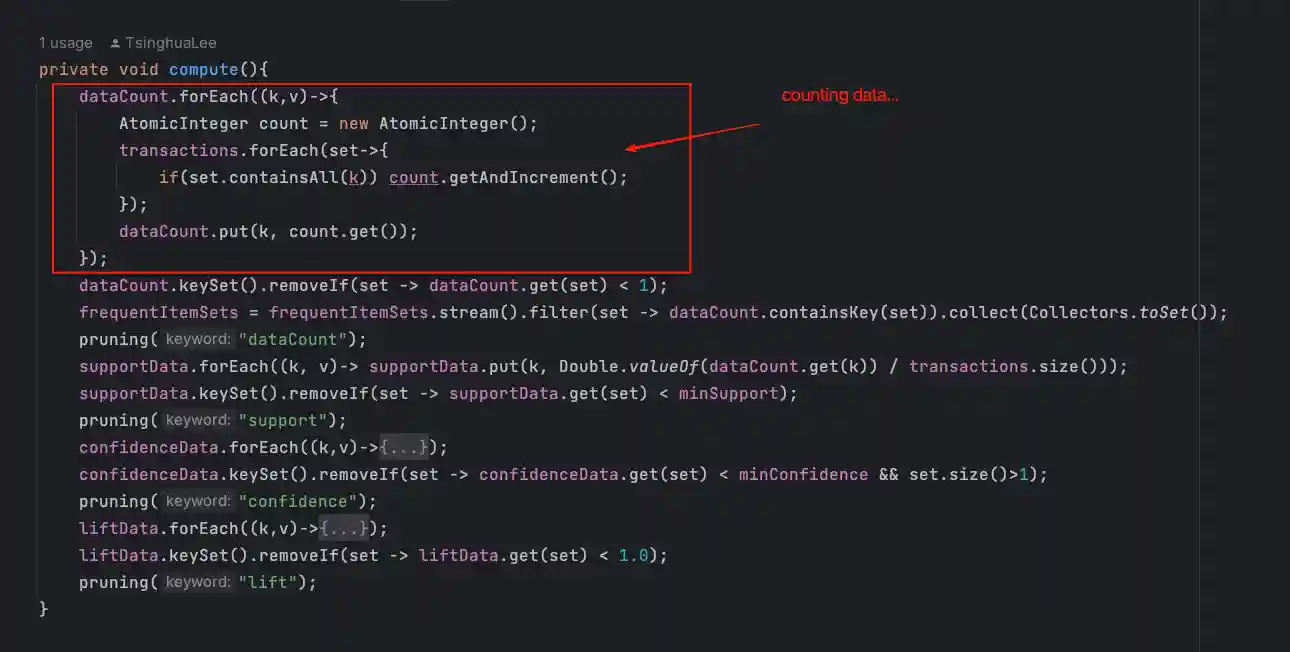
compute step1: 计算数据出现次数(dataCount)
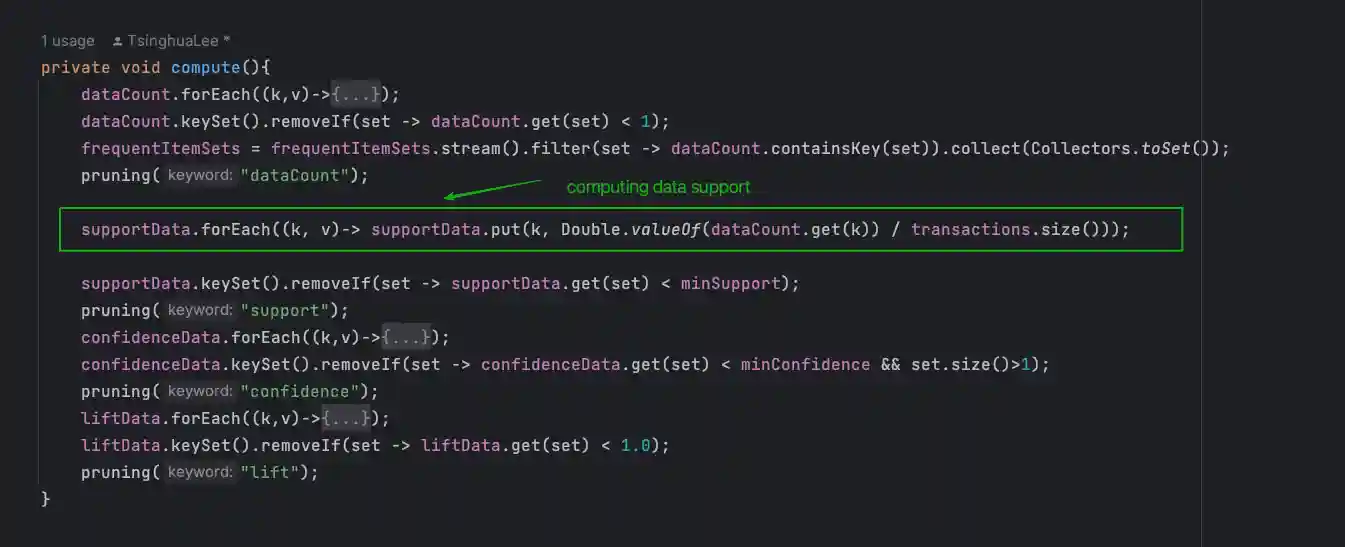
compute step2: 计算支持度(supportData)
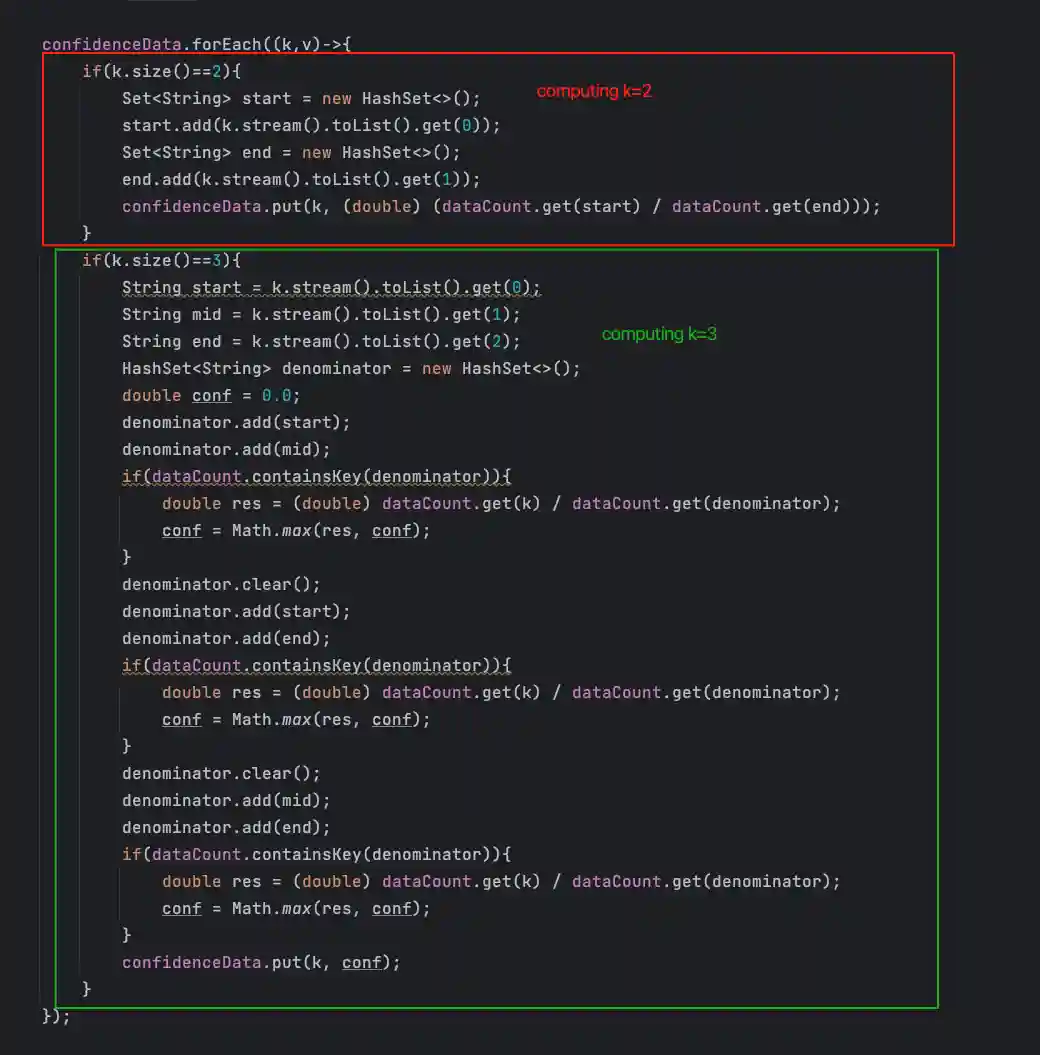
compute step3: 计算置信度(confidenceData)
compute step4: 计算提升度(liftData)
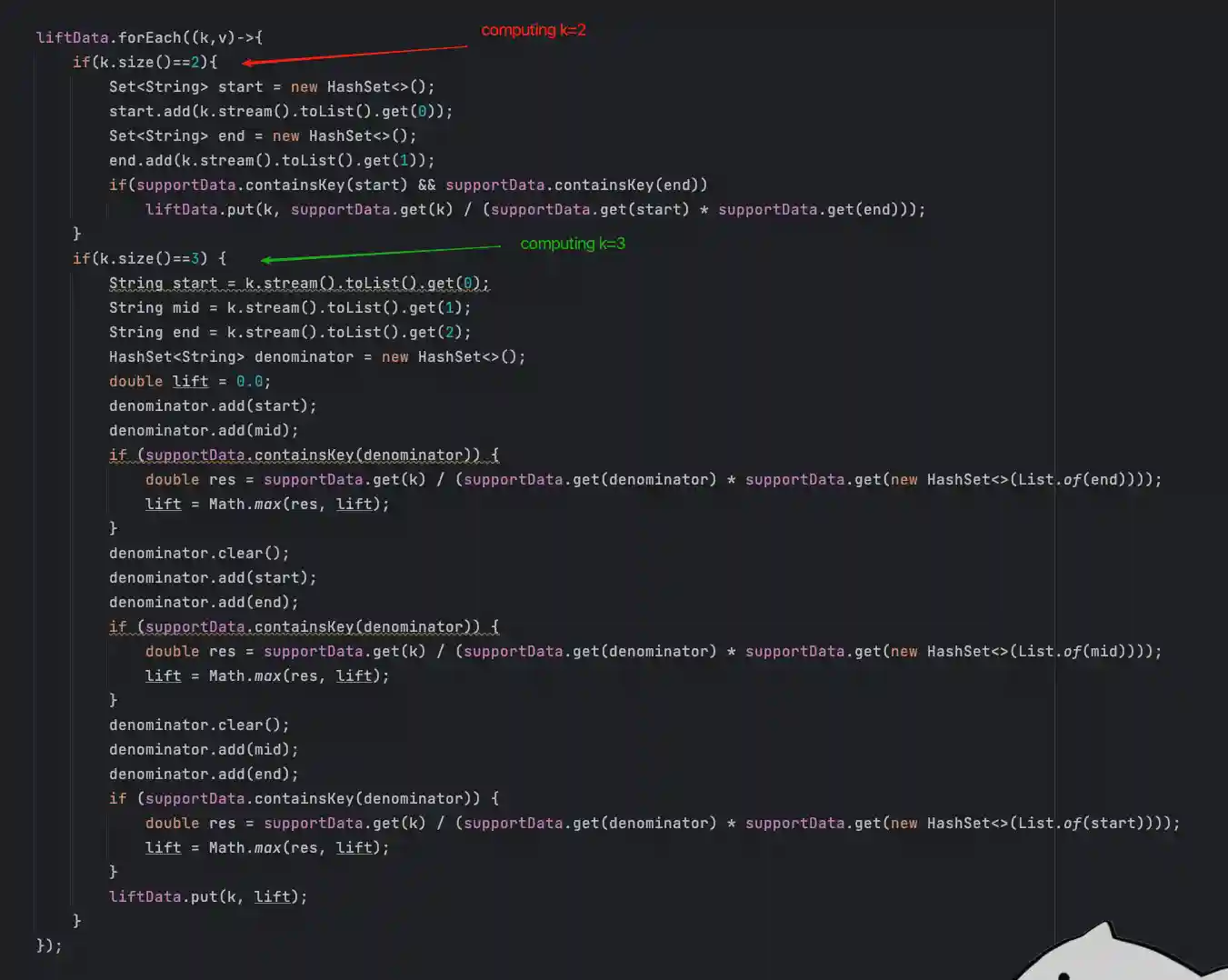
数据剪枝
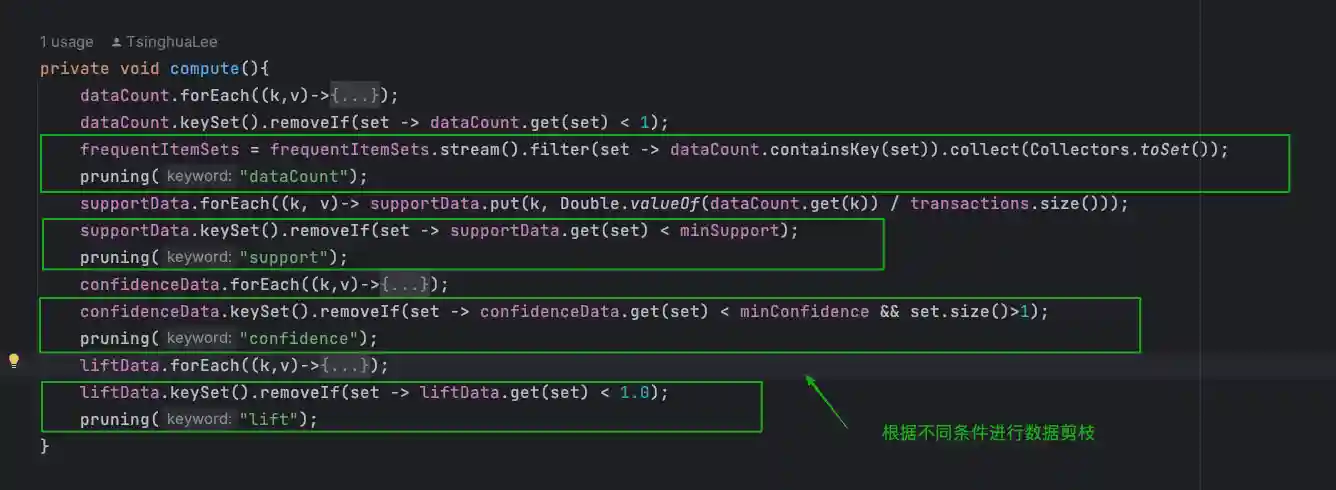
数据剪枝 - 去除不符合要求的数据。这时minSup、minConf就要参与判断了,这里我把剪枝抽象成了一个方法 pruning(String keyword) 根据keyword执行不同的操作,并在每个计算步骤完成后调用它
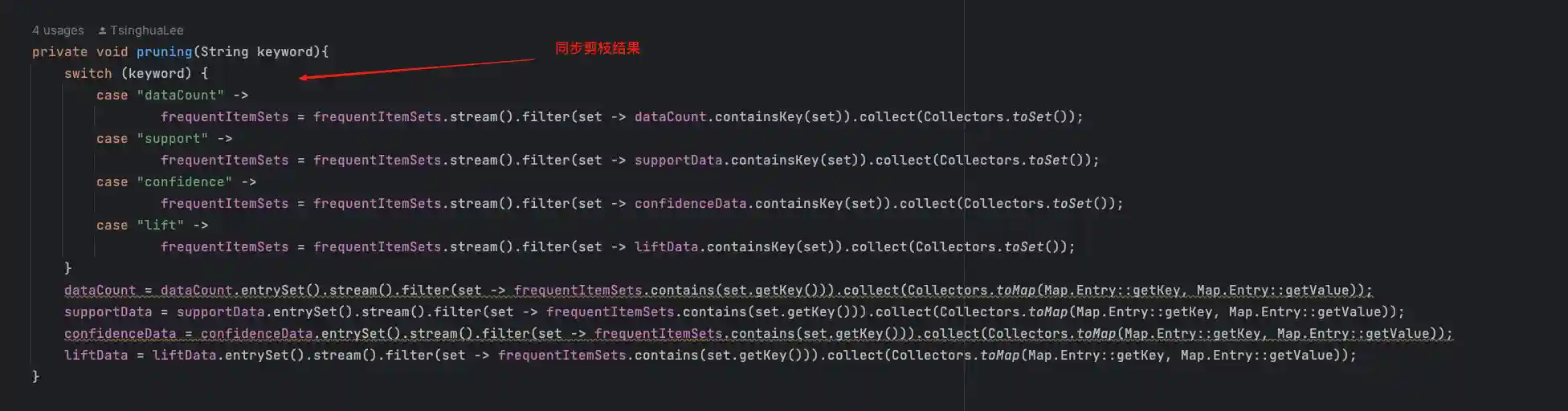
由于每一次剪枝的数据源都不同,所以pruning方法内以源为标准,对其他的容器都执行一次剪枝,以保证数据统一。以下是调用的位置
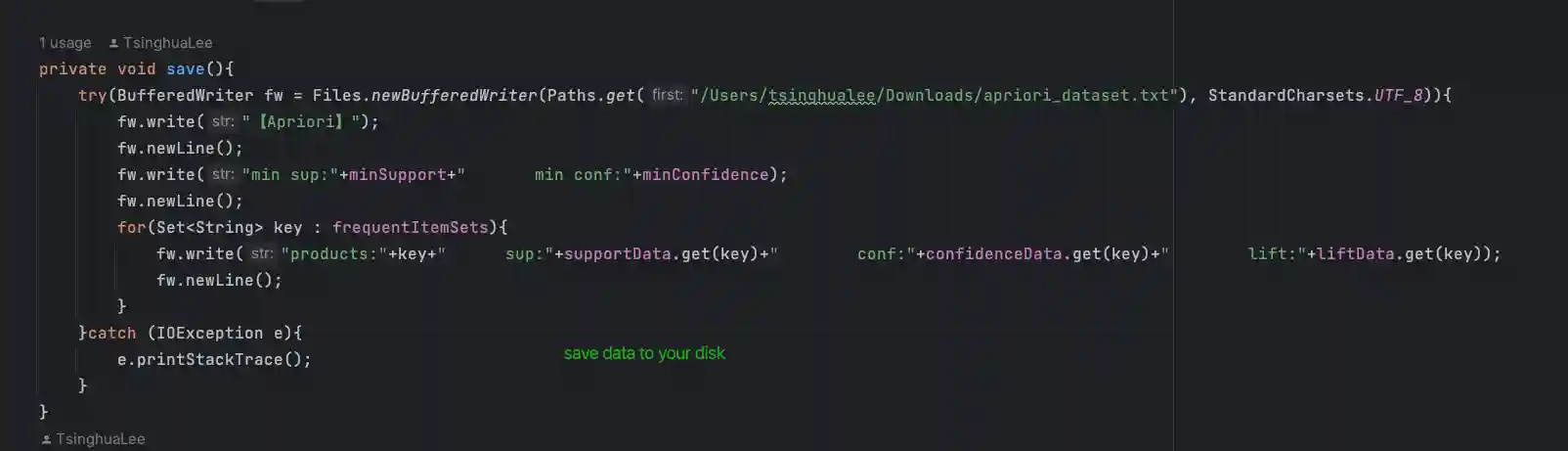
结果保存 - save()
在运算完成后,我这里使用NIO对结果进行了保存操作,读者可以自行处理结果。
完整代码
package com.fm.core.Utils;
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.*;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class Apriori extends Thread{
private final List<Set<String>> transactions = sql.get();
private final Double minSupport;
private final Double minConfidence;
private Set<Set<String>> frequentItemSets = new HashSet<>();
private Map<Set<String>, Integer> dataCount = new HashMap<>();
private Map<Set<String>, Double> supportData = new HashMap<>();
private Map<Set<String>, Double> confidenceData = new HashMap<>();
private Map<Set<String>, Double> liftData = new HashMap<>();
public Apriori(Double minSupport, Double minConfidence) {
this.minSupport = minSupport;
this.minConfidence = minConfidence;
}
private static final Supplier<List<Set<String>>> sql = ()->{
String url = "jdbc:mysql://127.0.0.1:3306/xxx?serverTimezone=UTC&useUnicode=yes&characterEncoding=utf8";
String user = "root";
String password = "xxx";
List<Set<String>> transactions = new ArrayList<>();
ArrayList<List<Integer>> pid_list = new ArrayList<>();
try(Connection connection = DriverManager.getConnection(url, user, password)){
Statement statement = connection.createStatement();
ResultSet rs = statement.executeQuery("SELECT products_id_array FROM orders");
while(rs.next()){
pid_list.add(Arrays.stream(rs.getString("products_id_array").split(",")).map(Integer::valueOf).toList());
}
}catch (Exception e){
e.printStackTrace();
}
try(Connection connection = DriverManager.getConnection(url, user, password)){
Statement statement = connection.createStatement();
for(List<Integer> list:pid_list){
Set<String> set = new HashSet<>();
for(Integer id:list){
ResultSet rs = statement.executeQuery("SELECT name FROM products where id="+id);
while(rs.next()){
set.add(rs.getString("name"));
}
}
transactions.add(set);
}
}catch (Exception e){
e.printStackTrace();
}
return transactions;
};
private void init(){
transactions.forEach(dataset-> dataset.forEach(set->{
Set<String> k1 = new HashSet<>();
k1.add(set);
frequentItemSets.add(k1);
}));
Set<Set<String>> k1 = new HashSet<>(frequentItemSets);
for(int i=0;i<k1.size();i++){
for(int j=i+1;j<k1.size();j++){
Set<String> set = new HashSet<>();
set.addAll(k1.stream().toList().get(i));
set.addAll(k1.stream().toList().get(j));
frequentItemSets.add(set);
}
}
Set<Set<String>> k2 = new HashSet<>(frequentItemSets);
for(int i=0;i<k2.size();i++){
for(int j=i+1;j<k2.size();j++){
Set<String> set = new HashSet<>();
set.addAll(k2.stream().toList().get(i));
set.addAll(k2.stream().toList().get(j));
if(set.size()==3) frequentItemSets.add(set);
}
}
frequentItemSets.forEach(dataset->{
dataCount.put(dataset, 0);
supportData.put(dataset, 0.0);
confidenceData.put(dataset, 0.0);
liftData.put(dataset, 0.0);
});
}
private void pruning(String keyword){
switch (keyword) {
case "dataCount" ->
frequentItemSets = frequentItemSets.stream().filter(set -> dataCount.containsKey(set)).collect(Collectors.toSet());
case "support" ->
frequentItemSets = frequentItemSets.stream().filter(set -> supportData.containsKey(set)).collect(Collectors.toSet());
case "confidence" ->
frequentItemSets = frequentItemSets.stream().filter(set -> confidenceData.containsKey(set)).collect(Collectors.toSet());
case "lift" ->
frequentItemSets = frequentItemSets.stream().filter(set -> liftData.containsKey(set)).collect(Collectors.toSet());
}
dataCount = dataCount.entrySet().stream().filter(set -> frequentItemSets.contains(set.getKey())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
supportData = supportData.entrySet().stream().filter(set -> frequentItemSets.contains(set.getKey())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
confidenceData = confidenceData.entrySet().stream().filter(set -> frequentItemSets.contains(set.getKey())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
liftData = liftData.entrySet().stream().filter(set -> frequentItemSets.contains(set.getKey())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
private void compute(){
dataCount.forEach((k,v)->{
AtomicInteger count = new AtomicInteger();
transactions.forEach(set->{
if(set.containsAll(k)) count.getAndIncrement();
});
dataCount.put(k, count.get());
});
dataCount.keySet().removeIf(set -> dataCount.get(set) < 1);
frequentItemSets = frequentItemSets.stream().filter(set -> dataCount.containsKey(set)).collect(Collectors.toSet());
pruning("dataCount");
supportData.forEach((k, v)-> supportData.put(k, Double.valueOf(dataCount.get(k)) / transactions.size()));
supportData.keySet().removeIf(set -> supportData.get(set) < minSupport);
pruning("support");
confidenceData.forEach((k,v)->{
if(k.size()==2){
Set<String> start = new HashSet<>();
start.add(k.stream().toList().get(0));
Set<String> end = new HashSet<>();
end.add(k.stream().toList().get(1));
confidenceData.put(k, (double) (dataCount.get(start) / dataCount.get(end)));
}
if(k.size()==3){
String start = k.stream().toList().get(0);
String mid = k.stream().toList().get(1);
String end = k.stream().toList().get(2);
HashSet<String> denominator = new HashSet<>();
double conf = 0.0;
denominator.add(start);
denominator.add(mid);
if(dataCount.containsKey(denominator)){
double res = (double) dataCount.get(k) / dataCount.get(denominator);
conf = Math.max(res, conf);
}
denominator.clear();
denominator.add(start);
denominator.add(end);
if(dataCount.containsKey(denominator)){
double res = (double) dataCount.get(k) / dataCount.get(denominator);
conf = Math.max(res, conf);
}
denominator.clear();
denominator.add(mid);
denominator.add(end);
if(dataCount.containsKey(denominator)){
double res = (double) dataCount.get(k) / dataCount.get(denominator);
conf = Math.max(res, conf);
}
confidenceData.put(k, conf);
}
});
confidenceData.keySet().removeIf(set -> confidenceData.get(set) < minConfidence && set.size()>1);
pruning("confidence");
liftData.forEach((k,v)->{
if(k.size()==2){
Set<String> start = new HashSet<>();
start.add(k.stream().toList().get(0));
Set<String> end = new HashSet<>();
end.add(k.stream().toList().get(1));
if(supportData.containsKey(start) && supportData.containsKey(end))
liftData.put(k, supportData.get(k) / (supportData.get(start) * supportData.get(end)));
}
if(k.size()==3) {
String start = k.stream().toList().get(0);
String mid = k.stream().toList().get(1);
String end = k.stream().toList().get(2);
HashSet<String> denominator = new HashSet<>();
double lift = 0.0;
denominator.add(start);
denominator.add(mid);
if (supportData.containsKey(denominator)) {
double res = supportData.get(k) / (supportData.get(denominator) * supportData.get(new HashSet<>(List.of(end))));
lift = Math.max(res, lift);
}
denominator.clear();
denominator.add(start);
denominator.add(end);
if (supportData.containsKey(denominator)) {
double res = supportData.get(k) / (supportData.get(denominator) * supportData.get(new HashSet<>(List.of(mid))));
lift = Math.max(res, lift);
}
denominator.clear();
denominator.add(mid);
denominator.add(end);
if (supportData.containsKey(denominator)) {
double res = supportData.get(k) / (supportData.get(denominator) * supportData.get(new HashSet<>(List.of(start))));
lift = Math.max(res, lift);
}
liftData.put(k, lift);
}
});
liftData.keySet().removeIf(set -> liftData.get(set) < 1.0);
pruning("lift");
}
private void save(){
try(BufferedWriter fw = Files.newBufferedWriter(Paths.get("/Users/tsinghualee/Downloads/apriori_dataset.txt"), StandardCharsets.UTF_8)){
fw.write("【Apriori】");
fw.newLine();
fw.write("min sup:"+minSupport+" min conf:"+minConfidence);
fw.newLine();
for(Set<String> key : frequentItemSets){
fw.write("products:"+key+" sup:"+supportData.get(key)+" conf:"+confidenceData.get(key)+" lift:"+liftData.get(key));
fw.newLine();
}
}catch (IOException e){
e.printStackTrace();
}
}
@Override
public void run() {
init();
compute();
save();
}
public static void main(String[] args) {
new Apriori( 0.3, 0.7).start();
}
}写在最后
本章代码仅以电商领域(K=3)项集为例编写的Java代码,读者会发现该代码仍有优化空间。在其他领域,参数、项集、精准度均有所不同,读者应根据自己的领域,对算法进行调整及优化。一个例子并不能帮你解决现实的问题,您应该通过这篇文章以及更多的案例写出属于自己的代码。 anyway~ Don't coding for code.